ImageArg-Shared-Task-2023
Co-located with The 10th ArgMining Workshop at EMNLP 2023 in Singapore.
View Project Code on GitHub ImageArg/ImageArg-Shared-Task
Important Announcement:
[10/01] Full corpus is now available here.
[09/01] Paper submission due date is extended to 9/2 PM (AoE).
[08/01] Shared task leaderboard is out!
[07/19] Submission (predicted results) deadline is extended to 07/26 (AoE).
[07/17] Task submission (predicted results) portal is open here.
[07/08] Test data is out here.
[07/03] Update data-downloading scripts. Please pull the
new code.
The First Shared Task in Multimodal Argument Mining
There has been a recent surge of interest in developing methods and corpora to improve and evaluate persuasiveness in natural language applications. However, these efforts have mainly focused on the textual modality, neglecting the influence of other modalities. Liu et al. introduced a new multimodal dataset called ImageArg. This dataset includes persuasive tweets along with associated images, aiming to identify the image's stance towards the tweet and determine its persuasiveness score concerning a specific topic. The ImageArg dataset is a significant step towards advancing multimodal persuasive text analysis and opens up avenues for exploring the persuasive impact of images in social media. To further this goal, we designed this shared task, which utilizes the ImageArg dataset to advance multimodal persuasiveness techniques.
Participants are welcome to submit system description papers for the shared task. Accepted papers will be published in the proceedings of The 10th ArgMining Workshop. To participate, please fill in this registration form (Closed) and feel free to join ImageArg Slack for conversations.
1. The ImageArg Shared Task
The ImageArg dataset is composed of tweets (images and text) from controversial topics, namely gun control and abortion. The dataset contains 2-dimensions of annotations: Argumentative Stance (AS), Image Persuasiveness (IP), of which each dimension addresses a unique research question: 1) AS: does the tweet have an argumentative stance? 2) IP: does the tweet image make the tweet more persuasive?ImageArg Shared Task is divided into two subtasks. Participants can choose Task A or Task B, or both. Please be aware that some tweet content may be upsetting or triggering. Please read details about AS and IP in the paper if you are interested.
Subtask A: Argumentative Stance (AS) Classification
Given a tweet composed of a text and image, predict whether the given tweet Supports or Opposes the given topic, which is a binary classification. Two examples are shown below.

The left tweets express strong stance towards support gun control by indicating a house bill about the requirement of background check of all gun sales. The right tweet opposes gun control because it is inclined to self-defense.
Subtask A (AS Classification) Leaderboard
| Rank | Team Name | Attempt | Score |
|---|---|---|---|
| 1 | KnowComp | 4 | 0.8647 ★ |
| 2 | KnowComp | 5 | 0.8571 |
| 3 | KnowComp | 1 | 0.8528 |
| 4 | Semantists | 4 | 0.8506 ★ |
| 5 | Semantists | 3 | 0.8462 |
| 6 | Semantists | 5 | 0.8417 |
| 7 | KnowComp | 2 | 0.8365 |
| 8 | Semantists | 1 | 0.8365 |
| 9 | Semantists | 2 | 0.8365 |
| 10 | KnowComp | 3 | 0.8346 |
| 11 | Mohammad Soltani | 2 | 0.8273 ★ |
| 12 | Pitt Pixels | 2 | 0.8168 ★ |
| 13 | Mohammad Soltani | 1 | 0.8142 |
| 14 | Mohammad Soltani | 4 | 0.8093 |
| 15 | GC-HUNTER | 2 | 0.8049 ★ |
| 16 | Mohammad Soltani | 3 | 0.8000 |
| 17 | Pitt Pixels | 1 | 0.7910 |
| 18 | Mohammad Soltani | 5 | 0.7782 |
| 19 | GC-HUNTER | 1 | 0.7766 |
| 20 | IUST | 1 | 0.7754 ★ |
| 21 | IUST | 2 | 0.7752 |
| 22 | Pitt Pixels | 4 | 0.7710 |
| 23 | Pitt Pixels | 5 | 0.7415 |
| 24 | KPAS | 1 | 0.7097 ★ |
| 25 | ACT-CS | 4 | 0.6325 ★ |
| 26 | ACT-CS | 3 | 0.6178 |
| 27 | ACT-CS | 2 | 0.6116 |
| 28 | ACT-CS | 1 | 0.5863 |
| 29 | IUST | 3 | 0.5680 |
| 30 | Pitt Pixels | 3 | 0.5285 |
| 31 | feeds* | 1 | 0.4418 ★ |
Subtask B: Image Persuasiveness (IP) Classification
Given a tweet composed of text and image, predict whether the image makes the tweet text more Persuasive or Not, which is a binary classification task. Two examples are shown below.
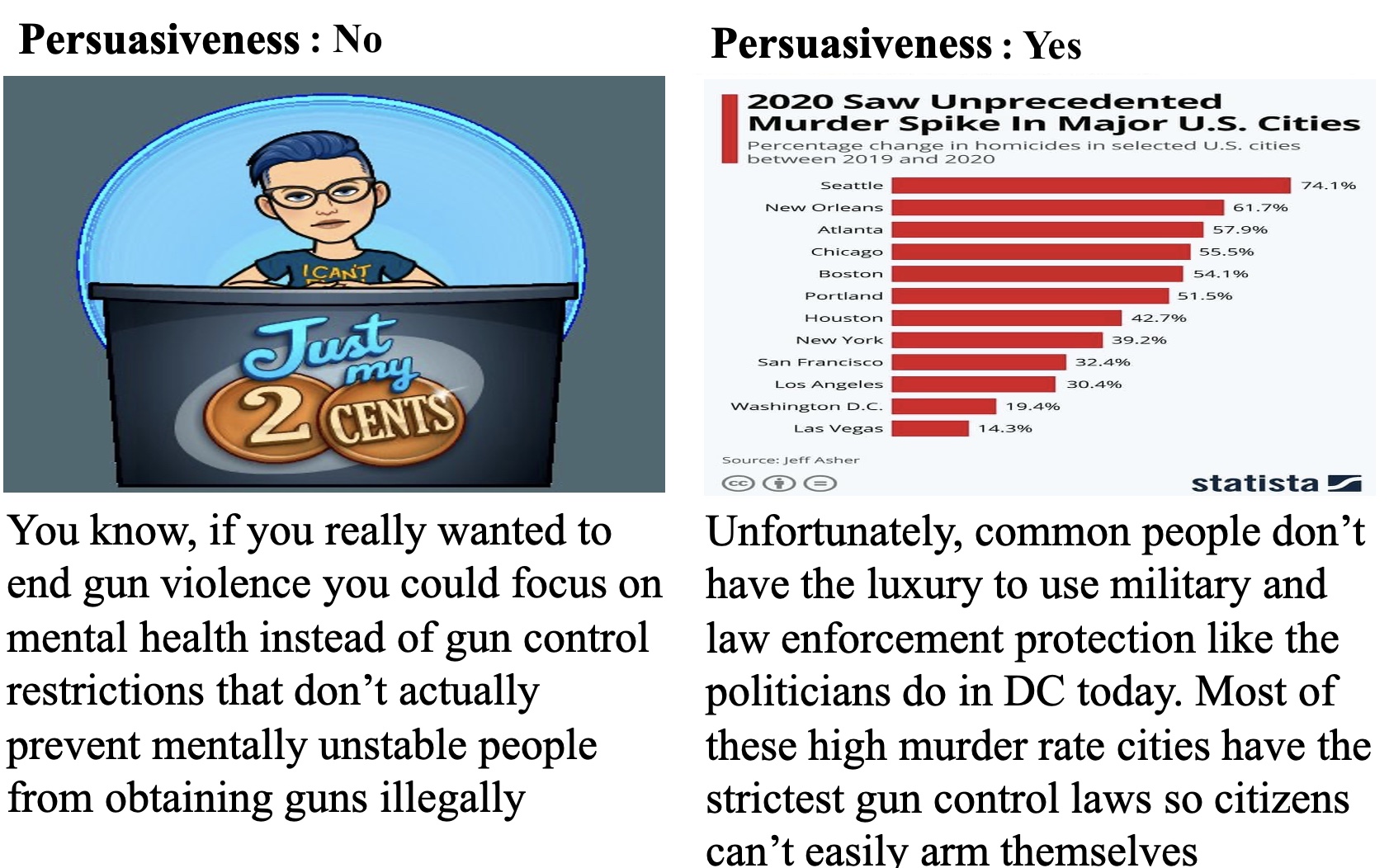
The left tweet has an image not even relevant to gun control topic. It does not improve the persuasiveness of the left tweet that argues to focus on mental health instead of gun restriction. The tweet image on the right makes the tweet text (and its stance) more persuasive because it provides strong evidence to show the statistics of the murder rate in major U.S. cities due to restrict gun control laws, so citizens cannot easily arm themselves.
Subtask B (IP Classification) Leaderboard
| Rank | Team Name | Attempt | Score |
|---|---|---|---|
| 1 | feeds | 1 | 0.5561 ★ |
| 2 | KPAS | 1 | 0.5417 ★ |
| 3 | feeds | 2 | 0.5392 |
| 4 | Mohammad Soltani | 5 | 0.5281 ★ |
| 5 | Semantists | 1 | 0.5045 ★ |
| 6 | ACT-CS | 1 | 0.5000 ★ |
| 7 | Mohammad Soltani | 1 | 0.4875 |
| 8 | Mohammad Soltani | 4 | 0.4778 |
| 9 | Mohammad Soltani | 3 | 0.4762 |
| 10 | Semantists | 5 | 0.4659 |
| 11 | IUST | 1 | 0.4609 ★ |
| 12 | Mohammad Soltani | 2 | 0.4545 |
| 13 | ACT-CS | 4 | 0.4432 |
| 14 | ACT-CS | 3 | 0.4348 |
| 15 | Semantists | 4 | 0.4222 |
| 16 | Semantists | 2 | 0.4141 |
| 17 | KnowComp | 1 | 0.3922 ★ |
| 18 | GC-HUNTER | 1 | 0.3832 ★ |
| 19 | ACT-CS | 2 | 0.3125 |
| 20 | Semantists | 3 | 0.2838 |
| 21 | Pitt Pixels | 1 | 0.1217 ★ |
2. Accepted Papers
The following system description papers submitted by the shared task participants have been peer-reviewed and accepted to the 10th ArgMining workshop, co-located at EMNLP 2023. The full proceedings are here.- A General Framework for Multimodal Argument Persuasiveness Classification of Tweets. Mohammad Soltani and Julia Romberg
- IUST at ImageArg: The First Shared Task in Multimodal Argument Mining. Melika Nobakhtian, Ghazal Zamaninejad, Erfan Moosavi Monazzah and Sauleh Eetemadi
- TILFA: A Unified Framework for Text, Image, and Layout Fusion in Argument Mining. Qing Zong, Zhaowei Wang, Baixuan Xu, Tianshi Zheng, Haochen Shi, Weiqi Wang, Yangqiu Song, Ginny Wong and Simon See
- Webis @ ImageArg 2023: Embedding-based Stance and Persuasiveness Classification. Islam Torky, Simon Ruth, Shashi Sharma, Mohamed Salama, Krishna Chaitanya, Tim Gollub, Johannes Kiesel and Benno Stein
- GC-Hunter at ImageArg Shared Task: Multi-Modal Stance and Persuasiveness Learning. Mohammad Shokri and Sarah Ita Levitan
- Argumentative Stance Prediction: An Exploratory Study on Multimodality and Few-Shot Learning. Arushi Sharma, Abhibha Gupta and Maneesh Bilalpur
- SPLIT: Stance and Persuasion Prediction with Multi-modal on Image and Textual Information. Jing Zhang, Shaojun Yu, Xuan Li, Jia Geng, Zhiyuan Zheng and Joyce Ho
- Semantists at ImageArg-2023: Exploring Cross-modal Contrastive and Ensemble Models for Multimodal Stance and Persuasiveness Classification. Kanagasabai Rajaraman, Hariram Veeramani, Saravanan Rajamanickam, Adam Maciej Westerski and Jung-Jae Kim
3. Dataset and Shared Task Submission
The dataset to download should only be used for scientific or research purposes. Any other use is explicitly prohibited. The datasets must not be redistributed or shared in part or full with any third party per Twitter Developer Policy. Redirect interested parties to this website.
All the tweets are instantly crawled from Twitter. Organizers are aware some tweets could not be available when participants start to download (e.g., a tweet could be deleted by its author). Organizers will regularly monitor the dataset to provide data patches that will replace invalid tweets with new annotated ones. Participants are required to fill out the Google Form (Closed) in order to receive data patches and the shared task updates.
Participants are allowed to extend only the training set with further (synthetic) samples. However, if do that, participants have to describe and the algorithm which extends the training set in the system description paper submission. This algorithm must be automatically executable without any human interaction (hence, without further manual annotation or manual user feedback).
Shared Task Evaluation: F1-score of participating teams will be used for ranking, but participants are free to include other metrics (e.g., AUC) in the system description paper submissions.
Shared Task Submission: There are up to 5 submissions from different approaches (systems) allowed per team and per subtask. Participants are allowed to withdraw your submission at anytime until the final deadline by contacting the organizers.
- Training and dev data download: Here
- Test data download: Here
- Evaluation script (submission format validation): Here
- Shared Task Submission: Here.
4. Call for Papers (System Description Papers)
The ImageArg Shared Task invites the submission of system description papers from all the teams that have a successful submission to the leaderboard. Accepted papers will be published in the proceedings of The 10th ArgMining Workshop.
By default, we only accept short papers (at most 4 pages, including references and optional appendix).
References do not count the 4-page limit and Appendices have no page limit. Authors will have one
extra page to address reviewers' comments in their camera-ready versions. Please note that all papers will be
treated equally in the workshop proceedings. Authors are expected to adhere to the ethical code set out in the ACL
Code of Ethics. Submissions that
violate any of the policies will be rejected without review.
At least one of the authors is required to be a reviewer and fill out this Reviewer Form. We will implement a double-blind review.
Structure of a system description paper could look as follows:
- Abstract
- Introduction
- Related work
- Task/Data
- Description of your approach
- Experiments & Results
- E.g., analyse your results and/or do an error analysis.
- E.g., analyze the result across topics or within each topic.
- E.g., add more experiments (if needed) based on your submission.
- Conclusion
- References
- Appendices (Optional)
Please cite the following two papers:
@inproceedings{liu-etal-2022-imagearg,
title = "{I}mage{A}rg: A Multi-modal Tweet Dataset for Image Persuasiveness Mining",
author = "Liu, Zhexiong and Guo, Meiqi and Dai, Yue and Litman, Diane",
booktitle = "Proceedings of the 9th Workshop on Argument Mining",
month = oct,
year = "2022",
address = "Online and in Gyeongju, Republic of Korea",
publisher = "International Conference on Computational Linguistics",
url = "https://aclanthology.org/2022.argmining-1.1",
pages = "1--18"
}
@inproceedings{liu-etal-2023-overview,
title = "Overview of {I}mage{A}rg-2023: The First Shared Task in Multimodal Argument Mining",
author = "Liu, Zhexiong and Elaraby, Mohamed and Zhong, Yang and Litman, Diane",
booktitle = "Proceedings of the 10th Workshop on Argument Mining",
month = Dec,
year = "2023",
address = "Online and in Singapore",
publisher = "Association for Computational Linguistics"
}
Paper Format: EMNLP 2023 style sheets.
Paper Submission: Please select ImageArg Shared Task from the Submission Categories dropdown located in the middle of the Submission Form; otherwise, the organizers may not be able to receive your paper.
5. Timeline
- 05/15/23: Training and Dev scripts (data) released for both subtasks
- 07/07/23: Registration closed and Test scripts released for both subtasks
07/21/23: 07/26/2023: Shared task submission due.- 08/01/23: Leaderboard announcement for both tasks
09/01/23: 09/02/23: System description paper due(No Deadline Extension)- 10/02/23: Notification of paper acceptance
- 10/09/23: Camera-ready paper due
- 12/10/23: Workshop dates
6. Terms and Conditions
By participating in this task you agree to these terms and conditions. If, however, one or more of these conditions is a concern for you, email us, and we will consider if an exception can be made.
- By submitting results to this competition, you consent to the public release of your scores at this website and at ArgMining-2023 workshop and in the associated proceedings, at the task organizers’ discretion. Scores may include, but are not limited to, automatic and manual quantitative judgements, qualitative judgements, and such other metrics as the task organizers see fit. You accept that the ultimate decision of metric choice and score value is that of the task organizers.
- You further agree that the task organizers are under no obligation to release scores and that scores may be withheld if it is the task organizers’ judgement that the submission was incomplete, erroneous, deceptive, or violated the letter or spirit of the competition’s rules. Inclusion of a submission’s scores is not an endorsement of a team or individual’s submission, system, or science.
- A participant can be involved in one team. Participating in more than one team is not recommended, but
not forbidden (if the person does not apply the same approach in different teams)
- You must not use any data from the development split as training instances. You must not use any test instance in the training of the model (also not indirectly for model selection). Approaches that violate this data separation are disqualified.
- The usage of Large Language Models LLMs are permitted as long as they are freely available (eg. LLAMA). Paid APIs for LLMs for (eg. openAI API) will be scored and reported but will not be considered for final ranking to ensure fairness between teams who might not have these APIs available.
- Once the competition is over, we will release the gold labels, and you will be able to determine results
on various system variants you may have developed. We encourage you to report results on all of your
systems (or system variants) in the system-description paper. However, we will ask you to clearly
indicate the result of your official submission.
- We will make the final submissions of the teams public at some point after the evaluation period.
- The organizers and their affiliated institutions makes no warranties regarding the datasets provided, including but not limited to being correct or complete. They cannot be held liable for providing access to the datasets or the usage of the datasets.
- The dataset should only be used for scientific or research purposes. Any other use is explicitly prohibited.
- The datasets must not be redistributed or shared in part or full with any third party. Redirect interested parties to this website.
7. Organizing Committee
- Zhexiong Liu, Ph.D. Student of Computer Science
- Mohamed Elaraby, Ph.D. Student of Computer Science
- Yang Zhong, Ph.D. Student of Computer Science
- Diane Litman, Professor of Computer Science
- Contact: imagearg [at] gmail.com
- Affiliation: University of Pittsburgh
8. Program Committee
- Johannes Kiesel, Bauhaus-Universität Weimar
- Arun Balajiee Lekshmi Narayanan, University of Pittsburgh
- Melika Nobakhtian, Iran University of Science and Technology
- Rajaraman Kanagasabai, Institute for Infocomm Research, A*STAR
- Mohammad Shokri, Hunter College, CUNY
- Mohammad Soltani, Heinrich Heine University
- Ghazal Zamaninejad, Iran University of Science and Technology
- Jing Zhang, Emory University
- Qing Zong, Harbin Institute of Technology, Shenzhen